With the pandemic acting as an accelerant, the healthcare industry is embracing AI enthusiastically. According to a 2020 survey by Optum, 80% of healthcare organizations have an AI strategy in place, while another 15% are planning to launch one.
Vendors — including Big Tech companies — are rising to meet the demand. Google recently unveiled Med-PaLM 2, an AI model designed to answer medical questions and find insights in medical texts. Elsewhere, startups like Hippocratic and OpenEvidence are developing models to offer actionable advice to clinicians in the field.
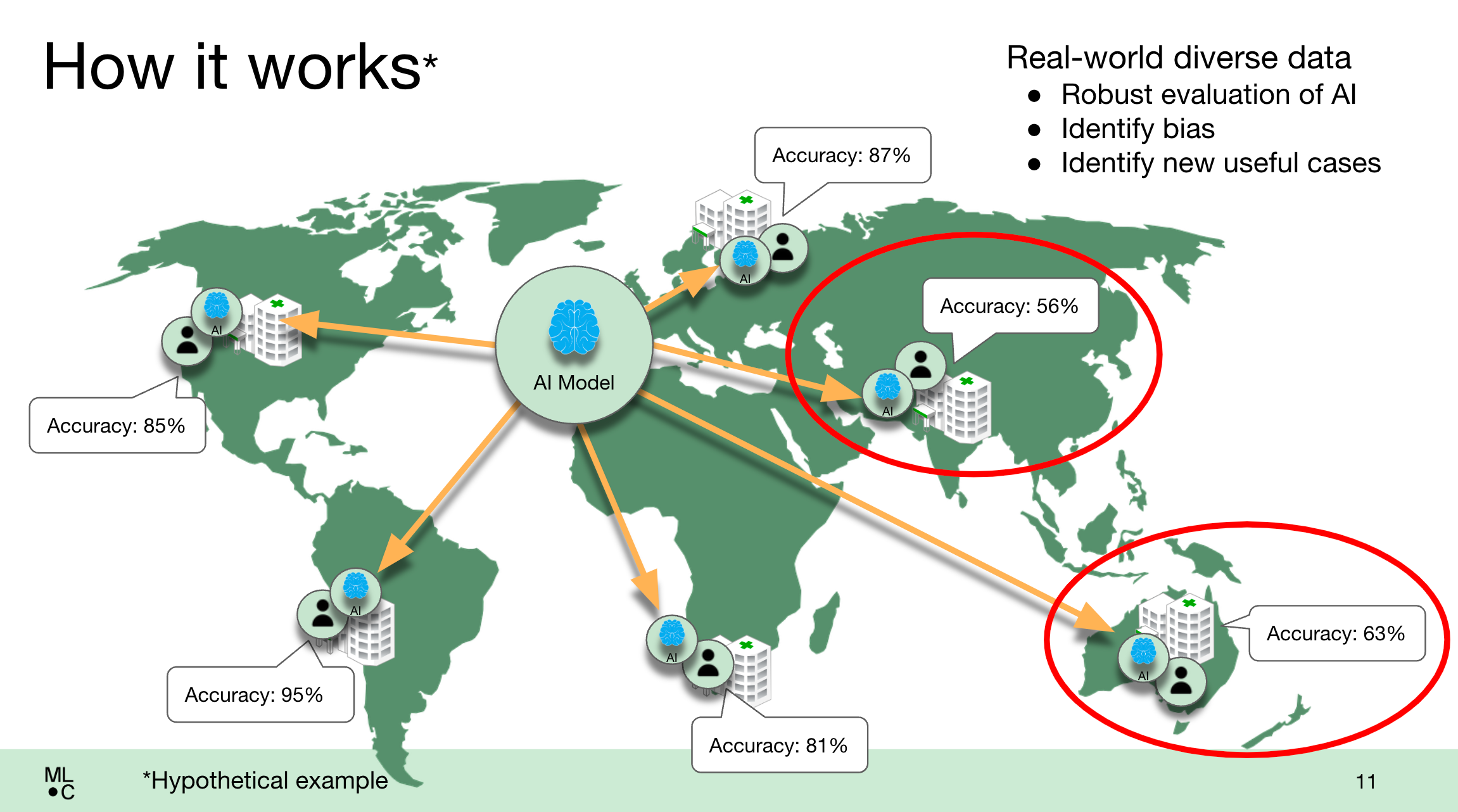
But as more models tuned to medical use cases come to market, it’s becoming increasingly challenging to know which models — if any — perform as advertised. Because medical models are often trained with data from limited, narrow clinical settings (e.g. hospitals along the Eastern seaboard), some show biases toward certain patient populations, usually minorities — leading to harmful impacts in the real world.
In an effort to establish a reliable, trusted way to benchmark and evaluate medical models, MLCommons, the engineering consortium focused on building tools for AI industry metrics, has architected a new testing platform called MedPerf. MedPerf, MLCommons says, can evaluate AI models on “diverse real-world medical data” while protecting patient privacy.
“Our goal is to use benchmarking as a tool to enhance medical AI,” Alex Karargyris, the co-chair of MLCommons Medical Working Group, which spearheaded MedPerf, said in a press release. “Neutral and scientific testing of models on large and diverse data sets can improve effectiveness, reduce bias, build public trust and support regulatory compliance.”
MedPerf, the result of a two-year collaboration led by the Medical Working Group, was built with input from both industry and academia — over 20 companies and more than 20 academic institutions gave feedback, according to MLCommons. (The Medical Working Group’s members span big corps like Google, Amazon, IBM and Intel as well as universities such as Brigham and Women’s Hospital, Stanford and MIT.)
In contrast to MLCommons’ general-purpose AI benchmarking suites, like MLPerf, MedPerf is designed to be used by the operators and customers of medical models — healthcare organizations — rather than vendors. Hospitals and clinics on the MedPerf platform can assess AI models on demand, employing “federated evaluation” to remotely deploy models and evaluate them on-premises.
MedPerf supports popular machine learning libraries in addition to private models and models available only through an API, like those from Epic and Microsoft’s Azure OpenAI Services.
An illustration of how the MedPerf platform works in practice.
In a test of the system earlier this year, MedPerf hosted the NIH-funded Federated Tumor Segmentation (FeTS) Challenge, a large comparison of models for assessing post-op treatment for glioblastoma (an aggressive brain tumor). MedPerf supported the testing of 41 different models this year, running both on-premises and in the cloud, across 32 healthcare sites on six continents.
According to MLCommons, all of the models showed reduced performance at sites with different patient demographics then the ones they were trained on, revealing the biases contained within.
“It’s exciting to see the results of MedPerf’s medical AI pilot studies, where all the models ran on hospital’s systems, leveraging pre-agreed data standards, without sharing any data,” Renato Umeton, director of AI operations at Dana-Farber Cancer Institute and another co-chair of the MLCommons Medical Working Group, said in a statement. “The results reinforce that benchmarks through federated evaluation are a step in the right direction toward more inclusive AI-enabled medicine.”
MLCommons sees MedPerf, which is mostly limited to evaluating radiology scan-analyzing models at present, as a “foundational step” toward its mission to accelerate medical AI through “open, neutral and scientific approaches.” It’s calling on AI researchers to use the platform to validate their own models across healthcare institutions and data owners to register their patient data to increase the robustness of MedPerf’s testing.
But this writer wonders if — assuming MedPerf works as advertised, which isn’t a sure thing — whether the platform truly tackles the intractable issues in AI for healthcare.
A recent revealing report compiled by researchers at Duke University reveals a massive gap between the marketing of AI and the months — sometimes years — of toil it takes to get the tech to work the right way. Often, the report found, the difficulty lies in figuring out how to incorporate the tech into the daily routines of doctors and nurses and the complicated care-delivery and technical systems that surround them.
It’s not a new problem. In 2020, Google released a surprisingly candid whitepaper that detailed the reasons its AI screening tool for diabetic retinopathy fell short in real-life testing. The roadblocks didn’t lie with the models necessarily, but rather the ways in which hospitals deployed their equipment, internet connectivity strength and even how patients responded to the AI-assisted evaluation.
Unsurprisingly, health care practitioners — not organizations — have mixed feelings about AI in healthcare. A poll by Yahoo Finance found that 55% believe the tech isn’t ready for use and only 26% believe it can be trusted.
That’s not to suggest medical model bias isn’t a real problem — it is, and it has consequences. System’s like Epic’s for identifying cases of sepsis, for example, have been found to miss many instances of the disease and frequently issue false alarms. It’s also true that gaining access to diverse, up-to-date medical data outside of free repositories for model testing hasn’t been easy for organizations that aren’t the size of, say, Google or Microsoft.
But it’s unwise to put too much stock into a platform like MedPerf where it concerns people’s health. Benchmarks only tell part of the story, after all. Safely deploying medical models requires ongoing, thorough auditing on the part of vendors and their customers – not to mention researchers. The absence of such testing is nothing short of irresponsible.
DUOS





